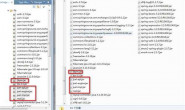
为什么在遍历根节点的子节点时,会在前面加#text,但是我在Xml文件里些的子节点只有name,id,data.求Help

Dom.xml代码如下:
<?xml version=”1.0″ encoding=”UTF-8″?>
<person catagory=”java”>
<name>zhangsan</name>
<id>444</id>
<data>19951115</data>
</person>
Dom.java代码如下:
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class Dom {
public static void main(String[] args) {
File f=new File(“G:\Dom.xml”);
DocumentBuilder db=null;
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
try{
db=dbf.newDocumentBuilder();
Document document=db.parse(f);
Element element=document.getDocumentElement();
System.out.println(“跟元素为”+element.getNodeName());
NodeList nl=element.getChildNodes();
System.out.println(nl.getLength());
for(int i=0;i<nl.getLength();i++){
Node node=nl.item(i);
System.out.println(node.getNodeName());
if(node.getNodeName().equals(“person”)){
System.out.println(“11″+node.getAttributes().getNamedItem(“catagory”).getNodeValue());
}
NodeList nl1=node.getChildNodes();
for(int i1=0;i1<nl1.getLength();i1++){
Node nodeDetail=nl1.item(i1);
if(“name”.equals(nodeDetail.getNodeName())){
System.out.println(“名字为:”+nodeDetail.getTextContent());
}else if(“id”.equals(nodeDetail.getNodeName())){
System.out.println(“id为:”+nodeDetail.getTextContent());
}else if(“data”.equals(nodeDetail.getNodeName())){
System.out.println(“生日为:”+nodeDetail.getTextContent());
}
}
}
}catch (Exception e){
e.printStackTrace();
}
}
}